SQLを持つ:説明、構文、例
SQLは、リレーショナルデータベースを扱うための標準言語です。彼はテーブルの形で保存されたデータを操作するための多くの強力なツールを備えています。

間違いなく、データをグループ化する能力はある特徴によるそれらのサンプリングはそのようなツールの1つである。 SQL HAVINGステートメントとWHERE句を使用すると、既に何らかの方法でグループ化されたデータのサンプリング条件を定義できます。
HAVING SQLパラメータ:description
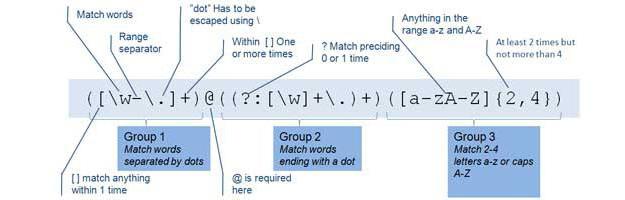
まず第一に、このパラメータオプションであり、GROUP BYパラメータとの組み合わせでのみ使用されます。覚えているように、GROUP BYは、SELECTが集計関数を使用するときに使用され、その計算結果は特定のグループによって取得される必要があります。 WHEREを使用すると、データがグループ化される前に選択条件を設定できます。HAVINGには、グループ自体に既に存在するデータに関連する条件が含まれています。より理解を深めるために、下の図に示されているダイアグラムの例を見てみましょう。

これは、HAVING SQLの説明を与える素晴らしい例です。 テーブルには、製品名、それらを生産する企業、およびその他のフィールドのリストが示されています。右上隅のクエリは、我々は2つの以上のアイテムを生産のみの企業を表示したい結果で、それぞれの会社が製造する製品のどのように多くの種類の情報を取得しようとしています。オプションBY GROUP製品(行)の数をカウントしたそれぞれが会社の名前に対応する3つのグループで構成されています。しかし、条件を満たすパラメータHAVINGは、条件を満たさないため、結果のサンプルから1つのグループを切り捨てます。その結果、製品5と3の数の企業に対応する2つのグループが得られます。
なぜ使用するのかという疑問が生じるかもしれませんSQLの中にWHEREがある場合に備えてください。 WHEREを使用した場合、グループ内ではなくテーブル内の行の総数が調べられ、条件はこの場合意味がありません。しかし、非常にしばしばそれらは1つの要求で完全に共存する。
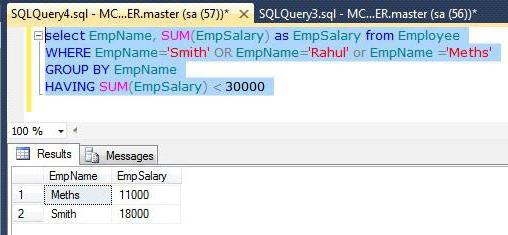
上記の例では、まず、さらに、各従業員の給与の合計によって試験される結果は、グループ内のWHEREパラメータで指定され、その後、グループ化された従業員に代わってデータの選択があります。
SQL HAVINGパラメータ:例、構文
構文のいくつかの機能を考えてみましょうSQLを持つ。このパラメータの説明は非常に簡単です。すでに述べたように第一に、それはパラメータGROUP BYと一緒に排他的に使用され、要求に存在する場合、直後およびORDER BYの前に示されています。 HAVINGは、既にグループ化されたデータのための条件を決定するので、それは、理解しやすいです。第二に、このパラメータの状態でのみ集計関数を使用することができ、フィールドは、パラメータGROUP BYに記載されています。このパラメータのすべての条件がの場合と同じように示されています。
結論
ご覧のとおり、この演算子では複雑なものはありませんいいえ。意味的には、WHEREと同じ方法で使用されます。 WHEREはすべての選択可能なデータに関連して使用され、HAVINGはGROUP BYパラメータで定義されたグループにのみ関連していることを理解することが重要です。私たちはHAVING SQLの包括的な説明を提示しました。これは、自信を持って作業するのに十分です。
</ p>